沒錯,k 大小值不同,會影響到分類的結果,以下示範不同的k 值會產生什麼樣的結果,下圖分別是k=3、7、10、20在同個種子所分布的狀況,種子碼為20180103。
set.seed(20180103)
kmeans_3 = kmeans(x = address_LatLng_data[, c('Lat','Lng')], centers = 3)
set.seed(20180103)
kmeans_7 = kmeans(x = address_LatLng_data[, c('Lat','Lng')], centers = 7)
set.seed(20180103)
kmeans_10 = kmeans(x = address_LatLng_data[, c('Lat','Lng')], centers = 10)
set.seed(20180103)
kmeans_20 = kmeans(x = address_LatLng_data[, c('Lat','Lng')], centers = 20)
result <- address_LatLng_data %>%
ungroup() %>%
mutate(category3 = kmeans_3$cluster,
category7 = kmeans_7$cluster,
category10 = kmeans_10$cluster,
category20 = kmeans_20$cluster)
k=3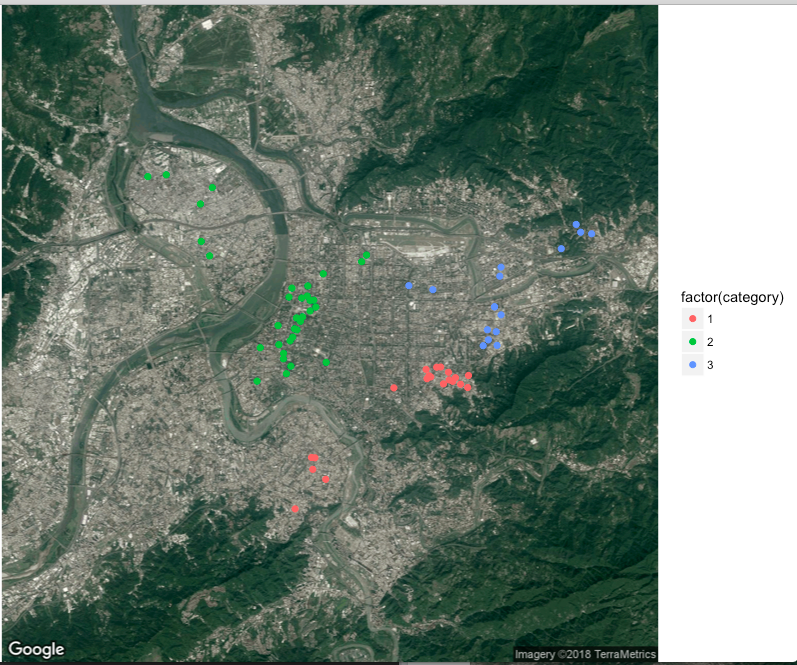
k=7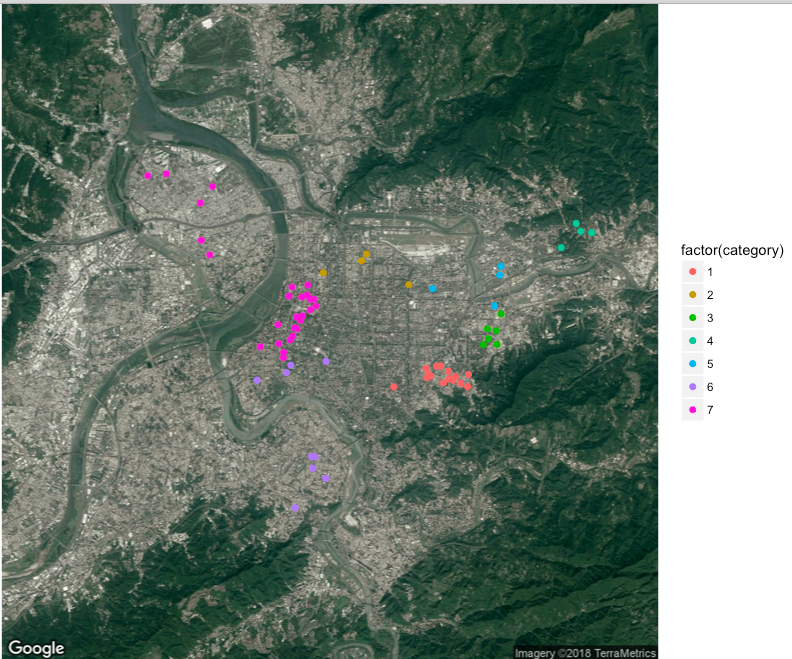
k=10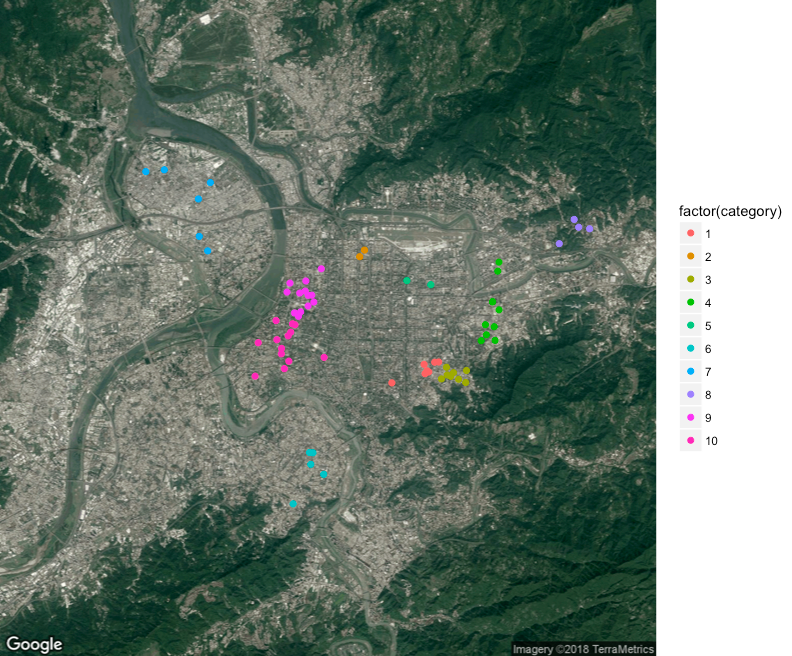
k=20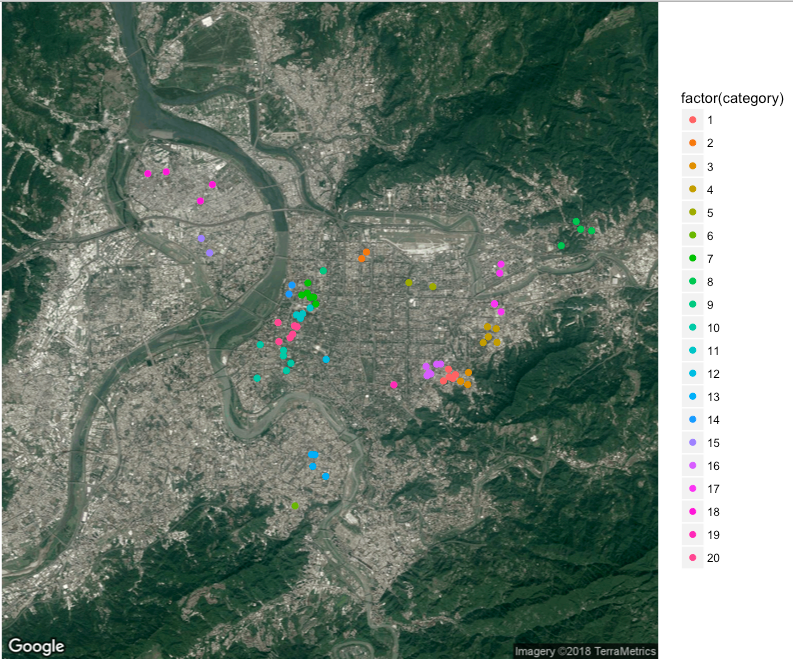
從不同的k 值可以觀察到,當k 值越大時,category 顆粒度可以越細,因此,諾我們使用很大的k,像西門一帶密集的地址區,可能會有些過於分類的現象出現,但如果k使用比較小的數字,有可能會發生像第一張圖的狀況,新北市的地址和台北市的地址是同一類的狀況。
所以這邊反問讀者,你們會如何決定k 的大小呢?
ref
day17原始碼



 iThome鐵人賽
iThome鐵人賽